 Blog
Blog

Indexing Solana's Jupiter with Cherry - An end-to-end tutorial in Python
Yule Andrade | 2025-05-16Most blockchain indexing tools are slow, with layers of unnecessary complexity involving YAML and config files, often leading to platform lock-in. But what if you could directly fetch, decode, and transform blockchain data using only Python and a few simple building blocks?
Cherry makes this possible.
Cherry is a pure Python framework built with a Rust backend for performance. It enables the creation of custom blockchain data pipelines, offering optimized querying of raw data, flexible decoding, and most importantly, the ability to use any Python tool you're familiar with, like pandas, polars, or duckdb, for transformations.
In this post, we'll walk through a real-world example: building a Solana indexer that fetches and decodes Jupiter DEX swap events, transforming them into a clean, queryable analytics table.
Here's what we'll cover:
- Setting up and querying: Connect to a multiple providers and fetch only the needed raw instructions, transactions, and blocks.
- Transforming and storing: Decode Solana instructions, join blocks data, and save the processed data to DuckDB or any other supported storage.
- Running and analyzing: Execute the pipeline and turn decoded events into a powerful DEX trades table ready for insights.
By the end of this tutorial, you'll see how Cherry provides full python experience over your indexing workflows without the usual complexity of learning a framework.
Cherry Pipelines: An Overview
In Cherry, pipelines define the entire data flow: from fetching raw data to transforming it and writing clean outputs into your storage of choice. You can easily customize or build pipelines to fit your exact indexing, decoding, and analytics needs.
You can build Cherry pipelines by following these steps:
- Defining a Provider - Cherry supports multiple providers for raw blockchain data across EVM and Solana networks. You can build pipelines on any chain your provider supports and even integrate new providers by making them compatible with Cherry's query interface.
- Querying - Queries let you specify precisely which blockchain data your pipeline needs, such as blocks, transactions, logs, and more. You can also control which fields (columns) to retrieve from each table, minimizing unnecessary data fetching and making your pipelines more efficient.
- Transformation Steps - Allows you to apply transformation steps to shape and prepare data before writing to storage. You can use popular Python data processing engines like Polars, PyArrow, Pandas, DataFusion, or DuckDB. Built-in transformation steps make it easy to:
- Cast types
- ABI/IDL decode data
- Validate records
- Encode data into hex or base58 strings
- Join columns from other tables
- Write to Database - Cherry allows you to write your processed data to various output formats or databases, making it easy to integrate into your existing data stack or experiment with new storage solutions. It supports a range of targets, including ClickHouse, Apache Iceberg, Delta Lake, DuckDB, Arrow Datasets, and Parquet files.
In many cases, you'll reuse the same pipeline structures. Cherry comes with many built-in pipelines (called datasets) for everyday use cases, but here we want to showcase its simplicity. In the next sections, we'll walk through each stage, using a real-world Solana example to show how easy and powerful Cherry pipelines can be. Throughout this guide, we'll skip over some boilerplate like imports to keep things focused, but don't worry, you'll find the complete Python file at the end if you'd like to replicate everything from scratch.
Defining a Provider
Before querying blockchain data, you must define a Provider—the component that connects to a blockchain indexer or node. Cherry is designed to support multiple providers, avoiding platform lock-in. A provider is configured through a ProviderConfig object, where you specify connection details, retry policies, and performance tuning options.
Providers are classified by their kind, depending on which network or service you interact with.
Cherry currently supports the following providers (ProviderKind), chosen for being free and high-performing:
- SQD — Connects to the SQD portal network, a decentralized network that serves historical data for EVM and Solana-compatible chains.
- Hypersync — Envio's hypersync is a high-speed, high-performance blockchain data retrieval system that supports several EVM networks.
- Yellowstone_grpc — Connects to a Yellowstone GRPC endpoint, primarily for Solana (SVM) data access.
For our example, we will use SQD:
provider = ProviderConfig(
kind=ProviderKind.SQD,
url="https://portal.sqd.dev/datasets/solana-mainnet",
)
Querying
The IngestQuery object defines what data to fetch from a provider, how to filter it, and which fields to return. Queries are specific to a blockchain type (QueryKind), and can be either:
- evm (for Ethereum and compatible chains) or
- svm (for Solana Virtual Machine chains).
Each query consists of field selectors (to specify what columns should be included in the response for each table) and a request (to select subsets of data and tables).
Here is our example query. Below, we will detail how it works.
query = IngestQuery(
kind=QueryKind.SVM,
params=Query(
from_block=from_block, # Required: Starting block number
to_block=to_block, # Optional: Ending block number
include_all_blocks=True, # Optional: Whether to include blocks with no matches in the tables request
fields=Fields( # Required: Which fields (columns) to return on each table
instruction=InstructionFields(
block_slot=True,
block_hash=True,
transaction_index=True,
instruction_address=True,
program_id=True,
data=True,
error=True,
),
block=BlockFields(
hash=True,
timestamp=True,
),
transaction=TransactionFields(
block_slot=True,
block_hash=True,
transaction_index=True,
signature=True,
),
),
instructions=[ # Optional: List of specific filters for instructions
InstructionRequest(
program_id=["JUP6LkbZbjS1jKKwapdHNy74zcZ3tLUZoi5QNyVTaV4"],
discriminator=["0xe445a52e51cb9a1d40c6cde8260871e2"],
include_transactions=True,
)
],
),
)
Field Selection
Field selection lets you precisely choose which data fields (columns) to retrieve, rather than fetching entire schemas. This minimizes bandwidth usage and speeds up processing. All fields default to False and must be explicitly enabled when needed. In this example, we are defining the fields for instructions (InstructionFields), blocks (BlockFields), and transactions (TransactionFields).
Filtering Specific Data
For both EVM and SVM, the query objects enable fine-grained row filtering through [table_name]Request objects. In our example, we are using the InstructionRequest to only fetch instructions in the block range that have program_id=["JUP…4"] and data starting with the discriminator=["0xe4…e2"]. Each request individually filters for a subset of rows in the tables. You can combine multiple requests to build complex queries tailored to your needs. Except for blocks, table selection is made through explicit inclusion in a dedicated request or an include_[table] parameter. In our example, we will receive:
- A block table that includes all blocks regardless of
InstructionRequest(because ofinclude_all_blocks=True) - An instruction table matching the
InstructionRequest(query has an explicit request for it) - A transaction table where transactions have instructions of the
InstructionRequest(because ofinclude_transactions=True)
The returned tables follow the field selection based on the specifications above.
Transformation Steps
Cherry provides multiple ways to transform query results before writing them to storage. Transformation steps are built-in processing operations that are applied sequentially during pipeline execution. Each step has a type (called kind) and an associated configuration that defines its behavior.
steps = [
cc.Step(
kind=cc.StepKind.SVM_DECODE_INSTRUCTIONS,
config=cc.SvmDecodeInstructionsConfig(
instruction_signature=instruction_signature,
hstack=True,
allow_decode_fail=True,
output_table="jup_swaps_decoded_instructions",
),
),
cc.Step(
kind=cc.StepKind.JOIN_SVM_TRANSACTION_DATA,
config=cc.JoinSvmTransactionDataConfig(),
),
cc.Step(
kind=cc.StepKind.JOIN_BLOCK_DATA,
config=cc.JoinBlockDataConfig(
join_blocks_on=["hash"],
join_left_on=["block_hash"],
),
),
cc.Step(
kind=cc.StepKind.BASE58_ENCODE,
config=cc.Base58EncodeConfig(),
),
]
Here's an overview of how transformation steps work:
- Select Step: Each transformation step defines a series of operations. This can range from data validation, decoding, encoding, and joining data, to custom transformations.
- Step Configuration: Each step has a configuration object that defines input parameters and/or modifies behavior. For example,
SvmDecodeInstructionsConfigrequires aninstruction_signatureand has configs for horizontally stacking raw and decoded columns, not stopping on failed rows, and naming the output table. - Process Flow: Steps are executed in the order they are provided. After each step, the data is updated, and the transformed data is passed to the next step in the pipeline.
In our example, we are:
- Decoding the Jupiter Aggregator v6 SwapEvent Instruction (more details below). Remember that this event has already been filtered in the query request by
program_idanddiscriminator, so our raw data only contains rows with this instruction. - Joining the transactions table with the instruction table (using default configs), bringing
block_timestampinto the instructions table. - Joining the transaction table with the instruction table (using default configs), bringing
transaction_signatureinto the instructions table. - Casting columns of Type bytes into base58 strings.
These are all built-in transformation steps, but you can also create and include a StepKind.CUSTOM, where the configs will take a parameter (runner) for a user-defined function. This allows maximum flexibility as you can define the exact transformations you need.
Decoding Solana Instructions and Logs
Cherry provides a flexible Solana decoding function, enabling pipelines to decode any instruction or Anchor log, as long as the user supplies the corresponding signature. This functionality is similar to what users are accustomed to in EVM pipelines. However, unlike EVM, where users can provide a string signature (e.g., "Transfer(address,address,uint256)"), Solana decoding requires constructing the signature using Cherry objects.
Signatures for Solana instructions and logs can be sourced from an IDL, SolScan, other blockchain explorers, or directly from public contract code. Below is an example from the Jupiter Aggregator v6 SwapEvent instruction.
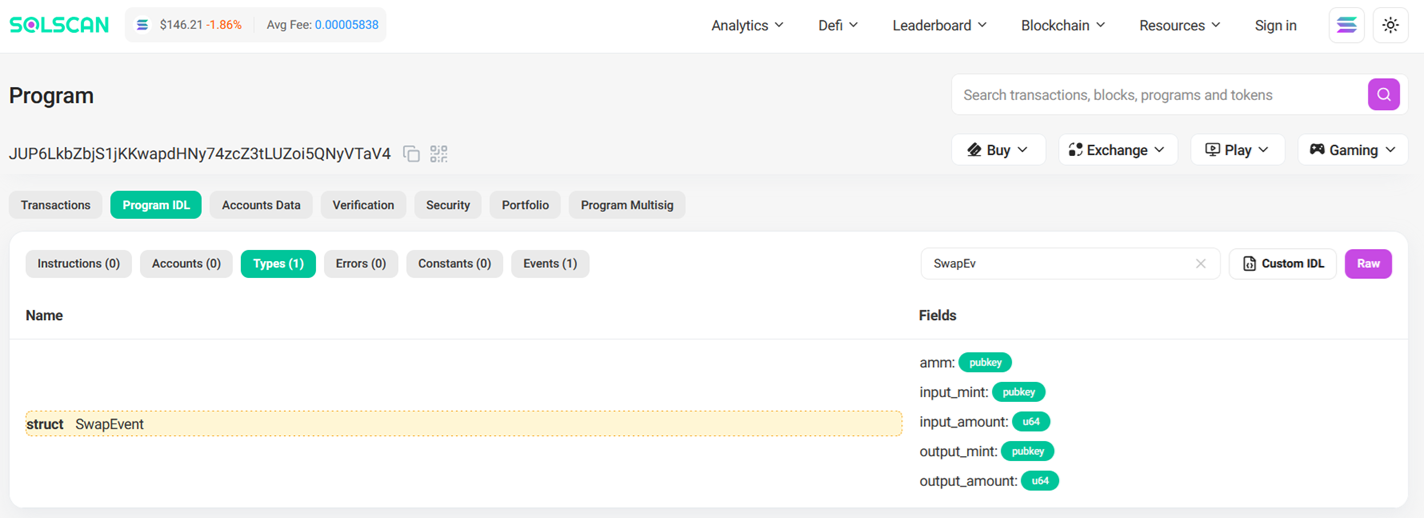
instruction_signature = InstructionSignature(
discriminator="0xe445a52e51cb9a1d40c6cde8260871e2",
params=[
ParamInput(
name="Amm",
param_type=FixedArray(DynType.U8, 32),
),
ParamInput(
name="InputMint",
param_type=FixedArray(DynType.U8, 32),
),
ParamInput(
name="InputAmount",
param_type=DynType.U64,
),
ParamInput(
name="OutputMint",
param_type=FixedArray(DynType.U8, 32),
),
ParamInput(
name="OutputAmount",
param_type=DynType.U64,
),
],
accounts_names=[],
)
👉 You can find additional information about Solana decoding in the "Decoding Solana Data" blog post.
Write to Database
Once data has been transformed, Cherry provides flexible options for writing the final output to different storage backends. Writers handle the writing phase, and each writer is responsible for persisting the data into a specific database or storage format.
We use DuckDB, but Cherry supports ClickHouse, Apache Iceberg, Delta Lake, Arrow Datasets, and Parquet files.
connection = duckdb.connect("data/solana_swaps.db")
writer = cc.Writer(
kind=cc.WriterKind.DUCKDB,
config=cc.DuckdbWriterConfig(
connection=connection.cursor(),
),
)
Running a Pipeline
Now that we have defined all the internal objects, we can create the Pipeline and run it:
pipeline = cc.Pipeline(
provider=provider,
query=query,
writer=writer,
steps=steps,
)
await run_pipeline(pipeline_name="jup_swaps", pipeline=pipeline)
And this is the jup_swaps_decoded_instructions written in the database as a result:
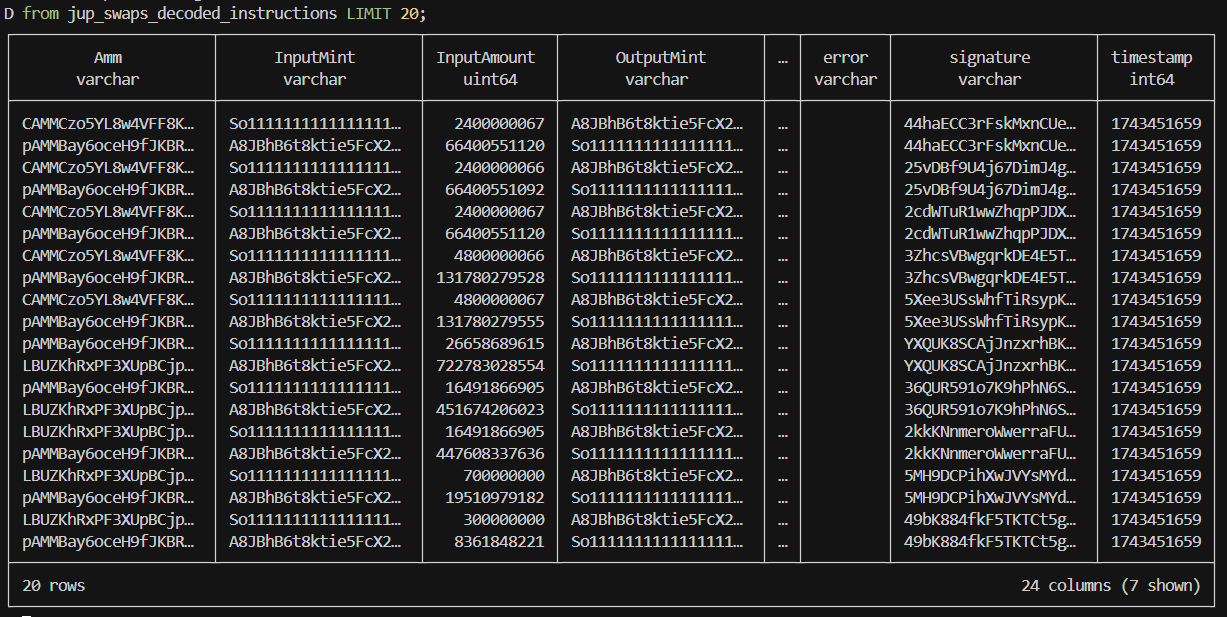
Analytics
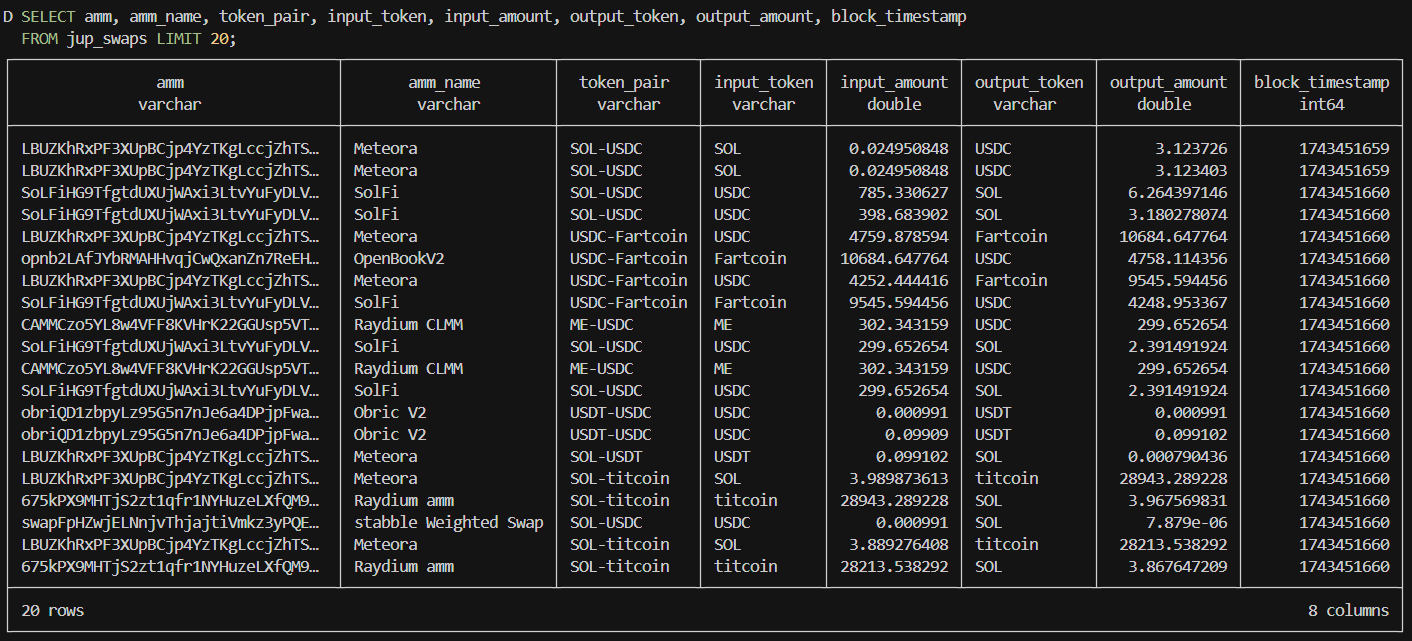
Lastly, although the pipeline above is simple, querying and decoding just a single instruction, it demonstrates how powerful the system can be for analytics, especially when combining data from multiple pipelines.
For example, we can transform the Jupiter Swap Event into a dex.trades swaps table, similar to what analytics platforms provide. While we plan to perform this transformation after ingestion, using DuckDB SQL, nothing prevents it from being integrated directly into the pipeline as an incremental transformation step.
connection.sql("""
CREATE OR REPLACE TABLE solana_amm AS
SELECT * FROM read_csv('examples/using_datasets/svm/solana_amm.csv');
CREATE OR REPLACE TABLE solana_tokens AS
SELECT * FROM read_csv('examples/using_datasets/svm/solana_tokens.csv');
CREATE OR REPLACE TABLE jup_swaps AS
SELECT
di.amm AS amm,
sa.amm_name AS amm_name,
case when di.inputmint > di.outputmint then it.token_symbol || '-' || ot.token_symbol
else ot.token_symbol || '-' || it.token_symbol
end as token_pair,
it.token_symbol as input_token,
di.inputmint AS input_token_address,
di.inputamount AS input_amount_raw,
it.token_decimals AS input_token_decimals,
di.inputamount / 10^it.token_decimals AS input_amount,
ot.token_symbol as output_token,
di.outputmint AS output_token_address,
di.outputamount AS output_amount_raw,
ot.token_decimals AS output_token_decimals,
di.outputamount / 10^ot.token_decimals AS output_amount,
di.block_slot AS block_slot,
di.transaction_index AS transaction_index,
di.instruction_address AS instruction_address,
di.timestamp AS block_timestamp
FROM jup_swaps_decoded_instructions di
LEFT JOIN solana_amm sa ON di.amm = sa.amm_address
LEFT JOIN solana_tokens it ON di.inputmint = it.token_address
LEFT JOIN solana_tokens ot ON di.outputmint = ot.token_address;
""")
connection.close()
Final Thoughts
Cherry offers a clean, Python-native approach to building custom blockchain indexers — all without vendor lock-in. While this post focused on Solana, the same building blocks apply to EVM chains as well.
With high-performance data access, flexible transformation steps, and broad support for storage backends, Cherry gives you the tools to create exactly the analytics pipelines you need — no boilerplate, no compromises.
Ready to dive deeper? Check out the Getting Started guide, and stay tuned for more deep dives and examples.
Complete End-to-End Code
The code here can get out-dated with the last improvements. You can also find this example in our repo: Decoding Jupiter swaps using cherry
# Cherry is published to PyPI as cherry-etl and cherry-core.
# To install it, run: pip install cherry-etl cherry-core
# Or with uv: uv pip install cherry-etl cherry-core
# You can run this script with:
# uv run examples/end_to_end/jup_swap.py --from_block 330447751 --to_block 330447751
# After run, you can see the result in the database:
# duckdb data/solana_swaps.db
# SELECT * FROM jup_swaps_decoded_instructions LIMIT 3;
# SELECT * FROM jup_swaps LIMIT 3;
################################################################################
# Import dependencies
import argparse
import asyncio
from pathlib import Path
from typing import Optional
import duckdb
from cherry_etl import config as cc
from cherry_etl.pipeline import run_pipeline
from cherry_core.svm_decode import InstructionSignature, ParamInput, DynType, FixedArray
from cherry_core.ingest import (
ProviderConfig,
ProviderKind,
QueryKind,
Query as IngestQuery,
)
from cherry_core.ingest.svm import (
Query,
Fields,
InstructionFields,
BlockFields,
TransactionFields,
InstructionRequest,
)
# Create directories
DATA_PATH = str(Path.cwd() / "data")
Path(DATA_PATH).mkdir(parents=True, exist_ok=True)
################################################################################
# Main function
async def main(
from_block: int,
to_block: Optional[int],
):
# Ensure to_block is not None, use from_block + 10 as default if it is
actual_to_block = to_block if to_block is not None else from_block + 10
# Defining a Provider
provider = ProviderConfig(
kind=ProviderKind.SQD,
url="https://portal.sqd.dev/datasets/solana-mainnet",
)
# Querying
query = IngestQuery(
kind=QueryKind.SVM,
params=Query(
from_block=from_block, # Required: Starting block number
to_block=actual_to_block, # Optional: Ending block number
include_all_blocks=True, # Optional: Weather to include blocks with no matches in the tables request
fields=Fields( # Required: Which fields (columns) to return on each table
instruction=InstructionFields(
block_slot=True,
block_hash=True,
transaction_index=True,
instruction_address=True,
program_id=True,
a0=True,
a1=True,
a2=True,
a3=True,
a4=True,
a5=True,
a6=True,
a7=True,
a8=True,
a9=True,
data=True,
error=True,
),
block=BlockFields(
hash=True,
timestamp=True,
),
transaction=TransactionFields(
block_slot=True,
block_hash=True,
transaction_index=True,
signature=True,
),
),
instructions=[ # Optional: List of specific filters for instructions
InstructionRequest(
program_id=["JUP6LkbZbjS1jKKwapdHNy74zcZ3tLUZoi5QNyVTaV4"],
discriminator=["0xe445a52e51cb9a1d40c6cde8260871e2"],
include_transactions=True,
)
],
),
)
# Defining an Instruction Signature
instruction_signature = InstructionSignature(
discriminator="0xe445a52e51cb9a1d40c6cde8260871e2",
params=[
ParamInput(
name="Amm",
param_type=FixedArray(DynType.U8, 32),
),
ParamInput(
name="InputMint",
param_type=FixedArray(DynType.U8, 32),
),
ParamInput(
name="InputAmount",
param_type=DynType.U64,
),
ParamInput(
name="OutputMint",
param_type=FixedArray(DynType.U8, 32),
),
ParamInput(
name="OutputAmount",
param_type=DynType.U64,
),
],
accounts_names=[],
)
# Transformation Steps
steps = [
cc.Step(
kind=cc.StepKind.SVM_DECODE_INSTRUCTIONS,
config=cc.SvmDecodeInstructionsConfig(
instruction_signature=instruction_signature,
hstack=True,
allow_decode_fail=True,
output_table="jup_swaps_decoded_instructions",
),
),
cc.Step(
kind=cc.StepKind.JOIN_SVM_TRANSACTION_DATA,
config=cc.JoinSvmTransactionDataConfig(),
),
cc.Step(
kind=cc.StepKind.JOIN_BLOCK_DATA,
config=cc.JoinBlockDataConfig(
join_blocks_on=["hash"],
join_left_on=["block_hash"],
),
),
cc.Step(
kind=cc.StepKind.BASE58_ENCODE,
config=cc.Base58EncodeConfig(),
),
]
# Write to Database
connection = duckdb.connect("data/solana_swaps.db")
writer = cc.Writer(
kind=cc.WriterKind.DUCKDB,
config=cc.DuckdbWriterConfig(
connection=connection.cursor(),
),
)
# Running a Pipeline
pipeline = cc.Pipeline(
provider=provider,
query=query,
writer=writer,
steps=steps,
)
await run_pipeline(pipeline_name="jup_swaps", pipeline=pipeline)
data = connection.sql("SELECT * FROM jup_swaps_decoded_instructions LIMIT 3")
print(f"Decoded Instructions:\n{data}")
# Post-pipeline Analytics
connection.sql("""
CREATE OR REPLACE TABLE solana_amm AS SELECT * FROM read_csv('examples/using_datasets/svm/solana_swaps/solana_amm.csv');
CREATE OR REPLACE TABLE solana_tokens AS SELECT * FROM read_csv('examples/using_datasets/svm/solana_swaps/solana_tokens.csv');
CREATE OR REPLACE TABLE jup_swaps AS
SELECT
di.amm AS amm,
sa.amm_name AS amm_name,
case when di.inputmint > di.outputmint then it.token_symbol || '-' || ot.token_symbol
else ot.token_symbol || '-' || it.token_symbol
end as token_pair,
it.token_symbol as input_token,
di.inputmint AS input_token_address,
di.inputamount AS input_amount_raw,
it.token_decimals AS input_token_decimals,
di.inputamount / 10^it.token_decimals AS input_amount,
ot.token_symbol as output_token,
di.outputmint AS output_token_address,
di.outputamount AS output_amount_raw,
ot.token_decimals AS output_token_decimals,
di.outputamount / 10^ot.token_decimals AS output_amount,
di.block_slot AS block_slot,
di.transaction_index AS transaction_index,
di.instruction_address AS instruction_address,
di.timestamp AS block_timestamp
FROM jup_swaps_decoded_instructions di
LEFT JOIN solana_amm sa ON di.amm = sa.amm_address
LEFT JOIN solana_tokens it ON di.inputmint = it.token_address
LEFT JOIN solana_tokens ot ON di.outputmint = ot.token_address;
""")
data = connection.sql("SELECT * FROM jup_swaps LIMIT 3")
print(f"Dex Trades Jupiter Swaps:\n{data}")
connection.close()
################################################################################
# CLI Argument Parser for starting and ending block
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Instructions tracker")
parser.add_argument(
"--from_block",
required=True,
help="Specify the block to start from",
)
parser.add_argument(
"--to_block",
required=False,
help="Specify the block to stop at, inclusive",
)
args = parser.parse_args()
from_block = int(args.from_block)
to_block = int(args.to_block) if args.to_block is not None else None
asyncio.run(main(from_block, to_block))