 Blog
Blog

Solana Pipelines with Cherry and SQD
Yule Andrade | 2025-05-22Cherry is fully open-source. Dive into the code, browse the docs, or contribute at https://github.com/steelcake/cherry.
Solana is blazing fast — and that's both its superpower and its challenge. With thousands of transactions per second, Solana produces an overwhelming amount of on-chain data. Making sense of that data is no small feat for developers, analysts, and protocol teams. The challenge isn't just keeping up—it's making sense of it all. Developers building on Solana often find themselves needing robust infrastructure not just to query data but also to transform, index, and serve it in real-time.
Cherry is a Python-native data pipeline framework explicitly designed for blockchains. Rather than forcing developers into rigid RPC interfaces or slow, centralized APIs, Cherry treats blockchain data as dynamic, structured tables—like blocks, transactions, and instructions—ready to be filtered, decoded, and transformed on your terms. It pairs Python's expressiveness with Rust's raw performance, letting you ingest, clean, and shape data using whatever engine you prefer—Polars, Pandas, DuckDB, or even your own custom modules. Cherry's approach is grounded in a simple but powerful idea: permissionless data access should be as fundamental as consensus.
That's where SQD.AI comes into play. For Solana, SQD bridges the gap between raw throughput and clean application data, letting developers define custom logic for extracting, filtering, and serving data to their apps. Combined with Cherry, the result is a robust pipeline tool, turning large amounts of blockchain data into something usable. This post will examine how both tools integrate into a Solana data exploration stack and how to use them to create fast, flexible, and resilient data-driven applications on Solana.
SQD: The Backbone for Scalable Onchain Data Access
At first glance, SQD might look like just another indexing layer—but under the hood, it represents a fundamental rethinking of how Web3 data should be accessed at scale. While traditional node RPCs are great for submitting transactions, they're notoriously inefficient for reading large amounts of data. They're rate-limited, centralized, and were never built to serve the kinds of real-time, high-throughput read operations demanded by modern blockchain applications.
SQD's Portal, however, is built from the ground up for this exact purpose. Instead of relying on overburdened public RPC endpoints or spinning up and maintaining your own node infrastructure, the Portal offers direct access to a unified stream of raw onchain data. This is not just faster—it's a paradigm shift in how developers interact with blockchain data.
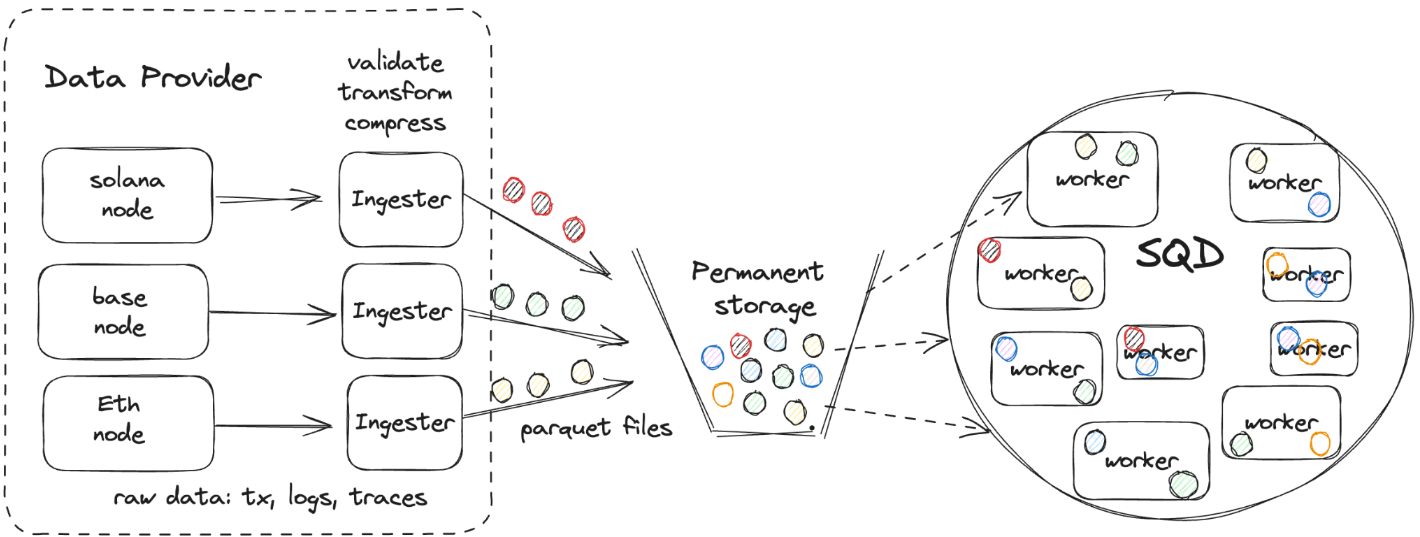
To understand what makes SQD so powerful, you must look at how it treats data. Rather than making repeated, narrow calls to a live node, SQD ingests blockchain data in bulk, serializes it into a columnar storage format, and distributes it across a global network of worker nodes. Each worker acts like a mini API server, serving cached data ranges with minimal latency. The result is a distributed, high-throughput data layer for blockchains. You can view it as a specialized "data layer" for blockchains optimized for performance, redundancy, and developer experience.
Cherry + SQD: Pipelines with Streaming Throughput
Cherry taps into the full power of SQD by integrating its Portal directly, making SQD one of Cherry's most robust and efficient data sources. This integration gives Cherry pipelines direct access to raw data from several chains, including Solana's, bypassing the limitations of fragile RPC endpoints and centralized APIs.
- SQD is about access—high-throughput, low-latency, decentralized infrastructure for retrieving onchain data.
- Cherry is about transformation—building robust, customizable pipelines that turn raw blockchain data into structured, actionable datasets.
Think of SQD as the data backbone and Cherry as the logic layer. SQD ensures you can tap into the full stream of Solana's activity. Cherry takes that stream and gives you tools to decode, validate, join, enrich, and feed it into your application logic, analytics stack, or warehouse.
The integration means you can now build end-to-end Solana data pipelines that:
- Stream gigabytes of data in parallel from Portal
- Decode and normalize it using Cherry's built-in Rust-backed transformations
- Process it using your preferred engine—Pandas, Polars, DuckDB, or even custom logic
- Output fresh, structured datasets continuously with schema inference and crash-resistance
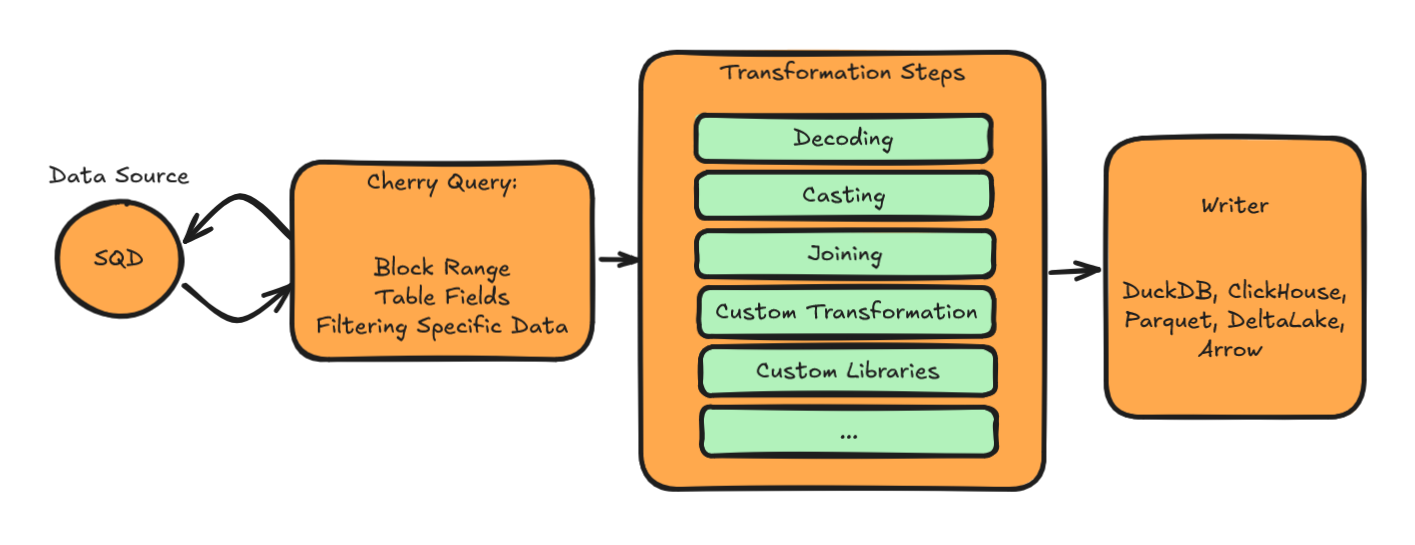
With SQD powering the raw data firehose and Cherry orchestrating the transformation, developers gain the best of both worlds: massively parallel data access and fully customizable pipelines—all in a single, streamlined workflow.
Real-World Use Cases
To understand what Cherry and SQD can do together, you must see them applied to real data. One example we've explored is indexing Jupiter swap events on Solana — pulling raw instructions from the chain, decoding them, and transforming them into a clean, analytics-ready table of DEX trades.
With Cherry, the entire pipeline is defined in Python: connecting to SQD, querying only the relevant transactions, decoding instructions using Cherry's flexible instruction signature system, and writing structured outputs to your database of choice. Thanks to the SQD integration, the data stream is fast, scalable, and entirely under your control.
provider = ProviderConfig(
kind=ProviderKind.SQD,
url="https://portal.sqd.dev/datasets/solana-mainnet",
)
query = IngestQuery(
kind=QueryKind.SVM,
params=Query(
from_block=from_block, # Required: Starting block number
to_block=to_block, # Optional: Ending block number
include_all_blocks=True, # Optional: Whether to include blocks with no matches in the tables request
fields=Fields( # Required: Which fields (columns) to return on each table
instruction=InstructionFields(...),
block=BlockFields(...),
transaction=TransactionFields(...)),
instructions=[ # Optional: List of specific filters for instructions
InstructionRequest(
program_id=["JUP6LkbZbjS1jKKwapdHNy74zcZ3tLUZoi5QNyVTaV4"],
discriminator=["0xe445a52e51cb9a1d40c6cde8260871e2"],
include_transactions=True)
],
),
)
instruction_signature = InstructionSignature(
discriminator="0xe445a52e51cb9a1d40c6cde8260871e2",
params=[
ParamInput(name="Amm", param_type=FixedArray(DynType.U8, 32)),
ParamInput(name="InputMint", param_type=FixedArray(DynType.U8, 32)),
ParamInput(name="InputAmount", param_type=DynType.U64),
ParamInput(name="OutputMint", param_type=FixedArray(DynType.U8, 32)),
ParamInput(name="OutputAmount", param_type=DynType.U64),
],
accounts_names=[],
)
steps = [
cc.Step(
kind=cc.StepKind.SVM_DECODE_INSTRUCTIONS,
config=cc.SvmDecodeInstructionsConfig(instruction_signature),
),
cc.Step(
kind=cc.StepKind.JOIN_SVM_TRANSACTION_DATA,
config=cc.JoinSvmTransactionDataConfig(),
),
cc.Step(
kind=cc.StepKind.JOIN_BLOCK_DATA,
config=cc.JoinBlockDataConfig(),
),
cc.Step(
kind=cc.StepKind.BASE58_ENCODE,
config=cc.Base58EncodeConfig(),
),
]
writer = cc.Writer(kind=cc.WriterKind.DUCKDB, config=cc.DuckdbWriterConfig(...))
pipeline = cc.Pipeline(
provider=provider,
query=query,
writer=writer,
steps=steps,
)
await run_pipeline(pipeline_name="jup_swaps", pipeline=pipeline)
This is done with a Python interface, giving you complete control over the data flow. Cherry pipelines are just regular Python objects, meaning you can build functions around them, reuse them across modules, or set input parameters to customize them as needed. This maximizes flexibility while minimizing code repetition, maintenance overhead, and accelerating the development process. And since it's all Python, you can bring in any custom libraries you want—whether for transformation, validation, analytics, or even machine learning.
We've published a detailed walkthrough of this pipeline in a dedicated post. If you want to see how the pieces come together, check out:
👉 Indexing Solana’s Jupiter with Cherry — An End-to-End Tutorial in Python.
Wrapping Up:
Without accessible, developer-friendly data tooling, Solana is locked away behind complexity, rate limits, and raw data formats that make building meaningful applications difficult. Cherry and SQD together offer a powerful, modular approach to working with its onchain data:
- SQD breaks the bottleneck of traditional RPC by turning raw blockchain history into a globally distributed, query-optimized data lake.
- Cherry turns this firehose into clean, structured pipelines that are fully customizable in Python, core engine optimized in Rust, and ready to plug into anything from dashboards to data warehouses.
Importantly, Cherry's vision aligns closely with SQD's: providing permissionless, scalable, and developer-friendly access to blockchain data—reducing friction and returning power to developers by making the whole history of a chain accessible, efficient, and composable.
It isn't just an upgrade to existing workflows — it's a shift in how we think about onchain data access altogether: stream-first, modular, and composable.
And the best part? This is just the beginning.
As both projects evolve, we're moving toward a world where high-throughput chains like Solana don't just produce data at scale — they empower developers to use that data effortlessly, creatively, and without compromise.
Fewer bottlenecks. Fewer black boxes. Just clean, open access to the truth of the chain.